

OpenCV + Tesseract is a powerful combination
When you are working on a Data Science project you may face the problem of mining pdf text. If the pdf document is text based, then usually it isn’t much trouble. There are a couple of python libraries like pdftotext or pdfminer that can handle that kind of problem with good results.
But what happens when the pdf document you are working with is not text based? For example it could be some old scans, or photograph of the documents that someone compiles into a pdf. With those kind of documents, the libraries I mentioned above don’t work. This is were this two powerful tools come in place. OpenCV is an open source BSD-licensed library developed by Intel that has dozens of computer vision algorithms. On the other hand, Tesseract is an open source OCR that has been financed by Google since 2006, since then it has become one of the top three OCR and can detect text in more that 100 languages.
The purpose of this post is to show you an example of how you can combine some of the features that this tools offer to solve the problem of mining a non text based pdf document. I am not going to go through the process of installing this libraries in you computer since there are plenty tutorials out there explaining how to do it.
1 .Convert PDF to image
The first step would be to convert every page of the pdf into image files.
To this end, we can use the pdf2image library.
import numpy as np
import pdf2image
import cv2 #OpenCV library for python
def convert_pdf_to_image(document, dpi):
images = []
images.extend(
list(
map(
lambda image: cv2.cvtColor(
np.asarray(image), code=cv2.COLOR_RGB2BGR
),
pdf2image.convert_from_path(document, dpi=dpi),
)
)
)
return images
The above function has two steps, the first one is to map every page of the pdf and converted to an image file. In this step you can specify the dpi for the generated image. The second one is to take each image and convert it to an array using the cv2 (OpenCV) library. The method cvtColor returns a numpy array where each element is a pixel of the image. This method expect the “code” parameter in which you specify the space conversion code. In the case of choosing COLOR_RGB2BGR, each element of the array will consist of 3 values (Red, Green and Blue) between 0 and 255.
Now we only need some pdf that we want to extract text from. For this example I pull 2 random pages of a pdf that is a scan of some book.
images = convert_pdf_to_image('example.pdf', 300)
Since the pdf consist of two pages we can see that the images variable is a list of length 2
# Number of pages in the pdf print(len(images))
2and each element of the images list will be a numpy array
print(images[0].shape)
(3301, 2550, 3)The number of pixels will vary depending on the dpi value you choose. Then, we can use matplotlib to visualize the resulting image.
import matplotlib.pyplot as plt first_page = images[0] # Let's work with the first page of the pdf plt.imshow(first_page)

Because we set a low value of dpi, the image is kind of blurry. But a higher definition not always guarantee a better performance of Tesseract. Is up to you to experiment and find out which options gives you the best output.
2. Tunning the image
OpenCV offers numerous methods to work with the images. For instance, the “Canny” method allows you to highlight edges in the image and the method “HoughLinesP” can help you detect straight lines. Let’s see how these two methods work together. Let’s start by converting the image to gray scale and then using the Canny method to detect the edges.
gray = cv2.cvtColor(first_page, cv2.COLOR_BGR2GRAY) edges = cv2.Canny(gray, 50,150,apertureSize = 3) plt.imshow(first_page )

Now that we have detected the edges, we can input this image to the HoughLinesP method. This will return a list with several numpy ndarray where each element has the coordinates of the starting and ending point of the line it detected. Since I’m only interested in the main lines, we can use the euclidean method from the scipy.spatial library to calculate the Euclidian distance between those points, and only keep the lines that are bigger than some length.
from scipy.spatial import distance
minLineLength = 100 # Min length of line. Line segments shorter than this are rejected.
maxLineGap = 10 # Maximum allowed gap between line segments to treat them as single line.
lines = cv2.HoughLinesP(edges,1,np.pi/180,200, minLineLength,maxLineGap)
for line in lines:
for x1,y1,x2,y2 in line:
if distance.euclidean((x1,y1), (x2,y2)) > 600:
cv2.line(first_page ,(x1,y1),(x2,y2),(0,255,0),2)
plt.imshow(first_page)

As you can see we now have detected the main lines inside the image and we highlight them in green. This feature is extremely useful when your are only interested in the text that is delimited by lines, since now that you have detected the lines inside the image, you can crop the image with only the section that you are interested in. So the next step will be classifying each line detected by its orientation. This can be done with a few lines of code.
def detect_orientation(all_lines):
vertical = []
horizontal = []
for line in all_lines:
for x1,y1,x2,y2 in line:
if distance.euclidean((x1,y1), (x2,y2)) > 600:
if x1 == x2:
vertical.append(line)
elif y1 == y2:
horizontal.append(line)
return vertical, horizontal
v, h = detect_orientation(lines)
Now that we have classified the lines we need the coordinates to crop the image. Looking back to our example, we can see that the text is between the top and bottom horizontal lines, and between the two rightmost vertical lines.
x = sorted([value[0,0] for value in v]) # create a list with all the x values in the vertical lines y = sorted([value[0,1] for value in h]) # create a list with all the y values in the horizontal lines x_min, x_max = x[-2], x[-1] y_min, y_max = y[0], y[-1] plt.imshow(first_page[ y_min:y_max, x_min:x_max])

3. Extracting the text
Now that we isolated the region of interest we are ready to extract the text inside that image. The Python-tesseract library is a wrapper that allows us to use the Google’s Tesseract-OCR Engine. For it to work, you’ll need to have installed tesseract-ocr in you operating system. Once you have it, it is pretty simple to use. The pytesseract library has two main methods, image_to_string and image_to_data, the first one as the name implies, returns a string with all the text that it could find. The second one can be used in conjunction with the pandas library to return a DataFrame with the coordinates and other metrics of every detected word.
import pytesseract
document_text = pytesseract.image_to_string(first[ y_min:y_max, x_min:x_max])
for line in document_text.split('\n'):
print(line)
———— SSS SS
properly at court. This frees the DM to think
about more important parts of the story
instead of little, perhaps even insignificant,
details.
Not everyone agrees with this! Some
DMs prefer to handle by themselves all the
situations covered by proficiencies. This
requires a quick wit and good memory. In
return, the DM is freed from the restraints of
rules. He can create the scene he wants
without worrying whether it breaks the rules.
But tread softly here—this is not an easy way
to judge a game! Try this only if you are
experienced at DMing or are a spontaneous
and entertaining storyteller.
Nonweapon proficiencies give a player
character more depth. Used cleverly, they
tell the player more about the personality
and background of his character and give
him more tools to work with. Applied judi-
ciously and thoughtfully, nonweapon profi-
ciencies vastly increase a character's
role-playing potential.
Beware, however, because nonweapon
proficiencies can have exactly the opposite
effect. They can become a crutch for play-
ers who are unwilling to role-play, an
excuse not to develop a character's per-
sonality or history. Some players decide
that proficiencies define everything the
character knows; they make no effort to
develop anything else.
Avoid this by encouraging players to dig
deeper and explore the possibilities in their
characters. Ask a player to explain why his
character has specific proficiencies. What did
that character do before becoming an
adventurer? Questions like this stimulate
players to delve into their characters’ per-
sonalities and backgrounds. Make a note of
the player's reasons and then you can use
them during play.
Nonweapon proficiencies can be used
to define the campaign and create
atmosphere. The proficiency lists can be
tailored to match specific regions or histori-
cal periods, or to define the differences
between nationalities.
If the characters’ home base is a fishing
village, the lists can be altered to allow all
characters to learn swimming, sailing, fish-
ing, and navigation at the same cost (in pro-
ficiency slots). These are common skills
among seafaring people.
At the same time, dwarves, who come to
this town from the nearby mountains, must
devote extra slots to learn these proficien-
cies. A youth spent in dry, solid tunnels has-
n't prepared them for a life at sea. Instead,
they can learn minines semcuttine and———— SSS SS
properly at court. This frees the DM to think
about more important parts of the story
instead of little, perhaps even insignificant,
details.
Not everyone agrees with this! Some
DMs prefer to handle by themselves all the
situations covered by proficiencies. This
requires a quick wit and good memory. In
return, the DM is freed from the restraints of
rules. He can create the scene he wants
without worrying whether it breaks the rules.
But tread softly here—this is not an easy way
to judge a game! Try this only if you are
experienced at DMing or are a spontaneous
and entertaining storyteller.
Nonweapon proficiencies give a player
character more depth. Used cleverly, they
tell the player more about the personality
and background of his character and give
him more tools to work with. Applied judi-
ciously and thoughtfully, nonweapon profi-
ciencies vastly increase a character's
role-playing potential.
Beware, however, because nonweapon
proficiencies can have exactly the opposite
effect. They can become a crutch for play-
ers who are unwilling to role-play, an
excuse not to develop a character's per-
sonality or history. Some players decide
that proficiencies define everything the
character knows; they make no effort to
develop anything else.
Avoid this by encouraging players to dig
deeper and explore the possibilities in their
characters. Ask a player to explain why his
character has specific proficiencies. What did
that character do before becoming an
adventurer? Questions like this stimulate
players to delve into their characters’ per-
sonalities and backgrounds. Make a note of
the player's reasons and then you can use
them during play.
Nonweapon proficiencies can be used
to define the campaign and create
atmosphere. The proficiency lists can be
tailored to match specific regions or histori-
cal periods, or to define the differences
between nationalities.
If the characters’ home base is a fishing
village, the lists can be altered to allow all
characters to learn swimming, sailing, fish-
ing, and navigation at the same cost (in pro-
ficiency slots). These are common skills
among seafaring people.
At the same time, dwarves, who come to
this town from the nearby mountains, must
devote extra slots to learn these proficien-
cies. A youth spent in dry, solid tunnels has-
n't prepared them for a life at sea. Instead,
they can learn minines semcuttine and———— SSS SS
properly at court. This frees the DM to think
about more important parts of the story
instead of little, perhaps even insignificant,
details.
Not everyone agrees with this! Some
DMs prefer to handle by themselves all the
situations covered by proficiencies. This
requires a quick wit and good memory. In
return, the DM is freed from the restraints of
rules. He can create the scene he wants
without worrying whether it breaks the rules.
But tread softly here—this is not an easy way
to judge a game! Try this only if you are
experienced at DMing or are a spontaneous
and entertaining storyteller.
Nonweapon proficiencies give a player
character more depth. Used cleverly, they
tell the player more about the personality
and background of his character and give
him more tools to work with. Applied judi-
ciously and thoughtfully, nonweapon profi-
ciencies vastly increase a character's
role-playing potential.
Beware, however, because nonweapon
proficiencies can have exactly the opposite
effect. They can become a crutch for play-
ers who are unwilling to role-play, an
excuse not to develop a character's per-
sonality or history. Some players decide
that proficiencies define everything the
character knows; they make no effort to
develop anything else.
Avoid this by encouraging players to dig
deeper and explore the possibilities in their
characters. Ask a player to explain why his
character has specific proficiencies. What did
that character do before becoming an
adventurer? Questions like this stimulate
players to delve into their characters’ per-
sonalities and backgrounds. Make a note of
the player's reasons and then you can use
them during play.
Nonweapon proficiencies can be used
to define the campaign and create
atmosphere. The proficiency lists can be
tailored to match specific regions or histori-
cal periods, or to define the differences
between nationalities.
If the characters’ home base is a fishing
village, the lists can be altered to allow all
characters to learn swimming, sailing, fish-
ing, and navigation at the same cost (in pro-
ficiency slots). These are common skills
among seafaring people.
At the same time, dwarves, who come to
this town from the nearby mountains, must
devote extra slots to learn these proficien-
cies. A youth spent in dry, solid tunnels has-
n't prepared them for a life at sea. Instead,
they can learn minines semcuttine andFor the second method the implementation is very similar
import pandas as pd df = pytesseract.image_to_data(first[ y_min:y_max, x_min:x_max], output_type=pytesseract.Output.DATAFRAME).dropna() df.head(10)
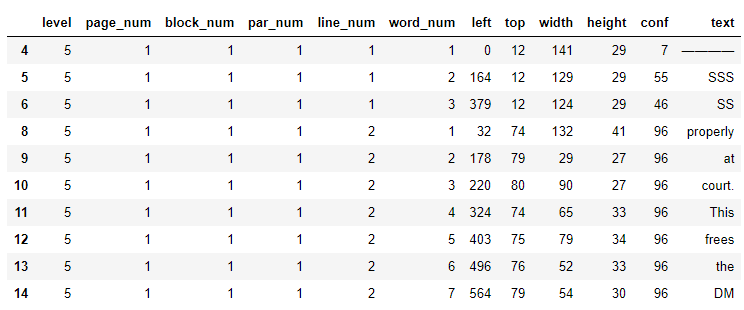
Here the columns left, top, width and height gives you the coordinates in pixels of a box surrounding the word that is in the text column. I find this second method very useful when you have certain patterns in your text. For example, lets suppose that the text you are interested in is always below a specific word; If that’s the case you can search for that word in the dataframe and use the top and left coordinates to crop the image in a similar fashion like we did using the OpenCV’s HoughLinesP method.
Additionally, these two methods accept a parameter called “config” where you can specify the OCR engine you want to use, the language of the text, and other features that can improve the output.
Like any other OCR, the result is not always perfect, but in my experience Tesseract does a pretty good job. Even in documents where the quality is far worse than the example we use here. So when you combine this powerful OCR with all the tools that OpenCV has to offer, you can get incredible results.